Adding Elements
The Bloom Filters data structure lets you add elements and check containment, just like a set. They have a guaranteed 0% false negative rate. However, the catch is they come with a very slight (0–2%) false positive rate depending on the volume of elements added.
Put simply, when a bloom filter tells you it doesn’t contain an element you can trust it to be correct, but when it says yes it does contain an element, it’s really just a maybe.
So why would anyone use a bloom filter instead of a set? A bloom filter configured to support a large number of unique elements will have a space footprint orders of magnitude smaller than a set holding the same number of unique elements.
This small trade off in accuracy for an enormous space savings ends up being very useful for certain system optimizations.
Let’s explore some visuals that show how they work and examples of where they can be applied to provide value.
Learn about Bloom Filters operations down below. OR: just get summarized in Bloom Filters
Adding Elements
In our example, we’ll take a bloom filter and add “Peter” and “Sam” string elements.
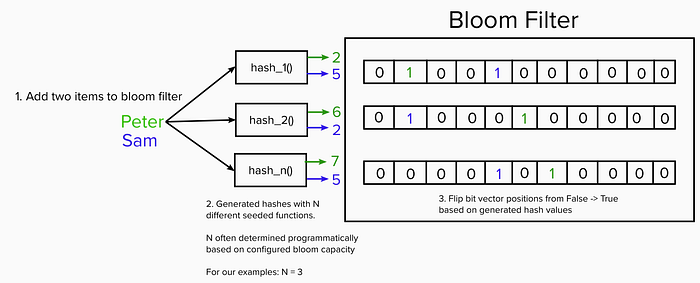
The bloom filter works by taking the elements, running them through N different hash functions each with an accompanying bit vector, and then setting to True the position in the accompanying vector based on the hash observed. Once the position is flipped True (1), it is never set back to False (0).
For Peter, the functions produce hashes 2, 6, and 7. It will set those positions from 0 → 1. Same for Sam at positions 5, 2, and 5.
The number of different hash functions N, as well as the length of the bit vectors, is usually reverse engineered in the implementation based on a configured capacity and maximum allowed error rate. Capacity is the number of distinct elements we expect to ever be seen by the bloom filter.
Containment Checks
Now let’s look at how it determines whether or not it contains an element.

In the case of Mary, we get hash values 3, 8, and 1 when we run it through our hash functions. None of those positions are set to True from our additions, so we report False for containment. This is the correct response.

For Steve, we get hashes 9, 2, and 6. The hash produced for Steve by the 2nd function collides with a hash produced earlier when we added Sam, which causes that one check to report True.
Fortunately, because the other two functions produced hashes that showed False values at their respective vector positions, the bloom filter will still correctly report False for the overall containment check. All three checks in our example must logically AND together to produce an overall True for containment.
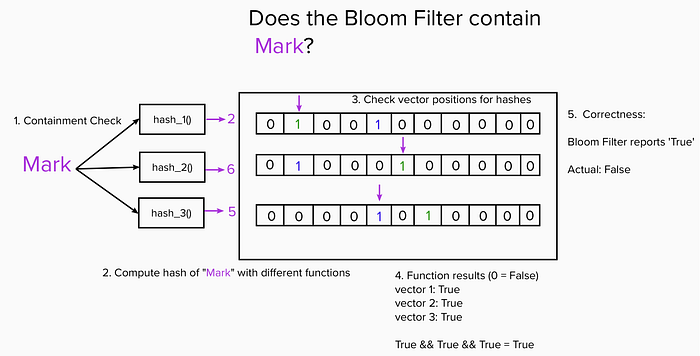
In Mark’s case, the hashes of 2, 6, and 5 by bad luck all happen to collide with earlier additions for Peter and Sam. In this case the bloom filter will see True across every bit vector, and incorrectly report True for containment, when in fact the bloom filter never saw the element “Mark”.
This is where the small error rate can kick in.
If we were checking for Peter or Sam, the check would see all the positions set to True for those entities and correctly respond True for containment. However in the general case a vector position could have been set True by a some other element with a colliding hash, so we can’t necessarily trust any answer as being 100% accurate.
The good news is the structure, by virtue of its design, can never accidentally state that an element was not in the system when it actually was (False negative). As soon as we add an element, the correct vector positions are flipped True and never flipped back to False.
So how is this structure useful to real systems when you can’t always trust containment accuracy for positive matches?
We can sometimes take advantage of the bloom filter’s small space requirements and zero false-negatives promise to try and avoid doing unnecessary work.
A few examples of Bloom Filter applications
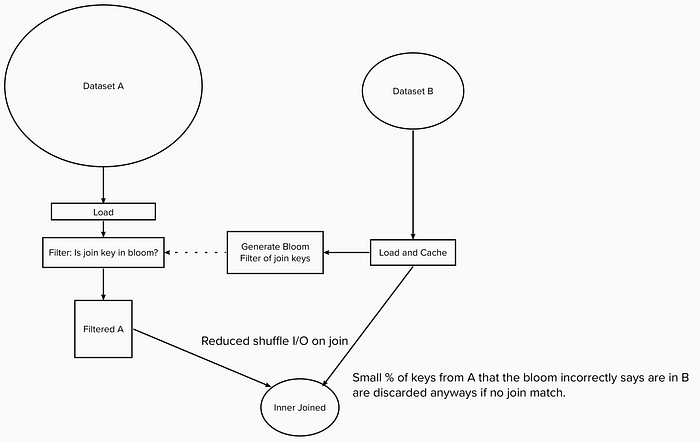
1. Inner join/Semi join cheat
If inner joining two datasets in Spark, one of gargantuan size and one of medium size, where a shuffle-join is inevitable, we can use a bloom filter to avoid shuffling rows from the gargantuan table that definitely don’t have a match in the medium table. Using a set to contain all the keys may not fit in machine memory, so this is where a bloom filter can shine.
Any false positives that sneak past the bloom filter will just get thrown away later during the inner join process.
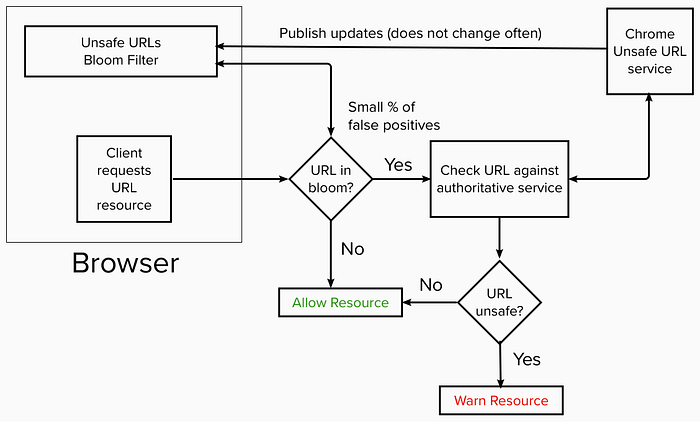
2. Chrome unsafe/malicious URLs client side check.
Chrome keeps a bloom filter to check client-side if a URL is definitely not malicious. Any false positives (URLs the bloom filter says are malicious, but are not) will just require a follow up remote service check and waste a little time validating them.
This preferable to checking the remote service every time only to be frequently told the URL is safe. Storing the unsafe URLs in a set residing in browser memory would be impractical because of the space required to hold every unique URL.
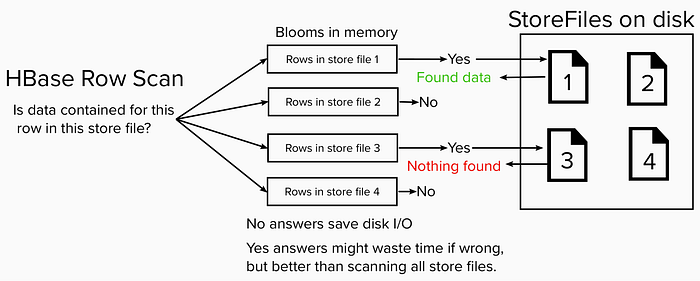
3. HBase row disk I/O savings by skipping StoreFiles.
Retrieving column family details for a given row sometimes requires reading multiple StoreFiles on disk. A bloom filter could save the trouble of scanning StoreFiles that don’t have any info pertaining to a given row.
Sources:
- Bloom Filter Join. https://issues.apache.org/jira/browse/SPARK-32268
- Google Safe Browsing: https://developers.google.com/safe-browsing/
- Nice Bloom Filter Application https://web.archive.org/web/20101027012345/http://blog.alexyakunin.com/2010/03/nice-bloom-filter-application.html
- Apache HBase: https://hbase.apache.org/
- HBase Bloom filters: https://issues.apache.org/jira/browse/HBASE-1200
- How are Bloom filters used in HBase: https://www.quora.com/How-are-bloom-filters-used-in-HBase