PortalJS https://portal.ckan-archive-test.sigma2.no/ CKAN https://admin.ckan-archive-test.sigma2.no/
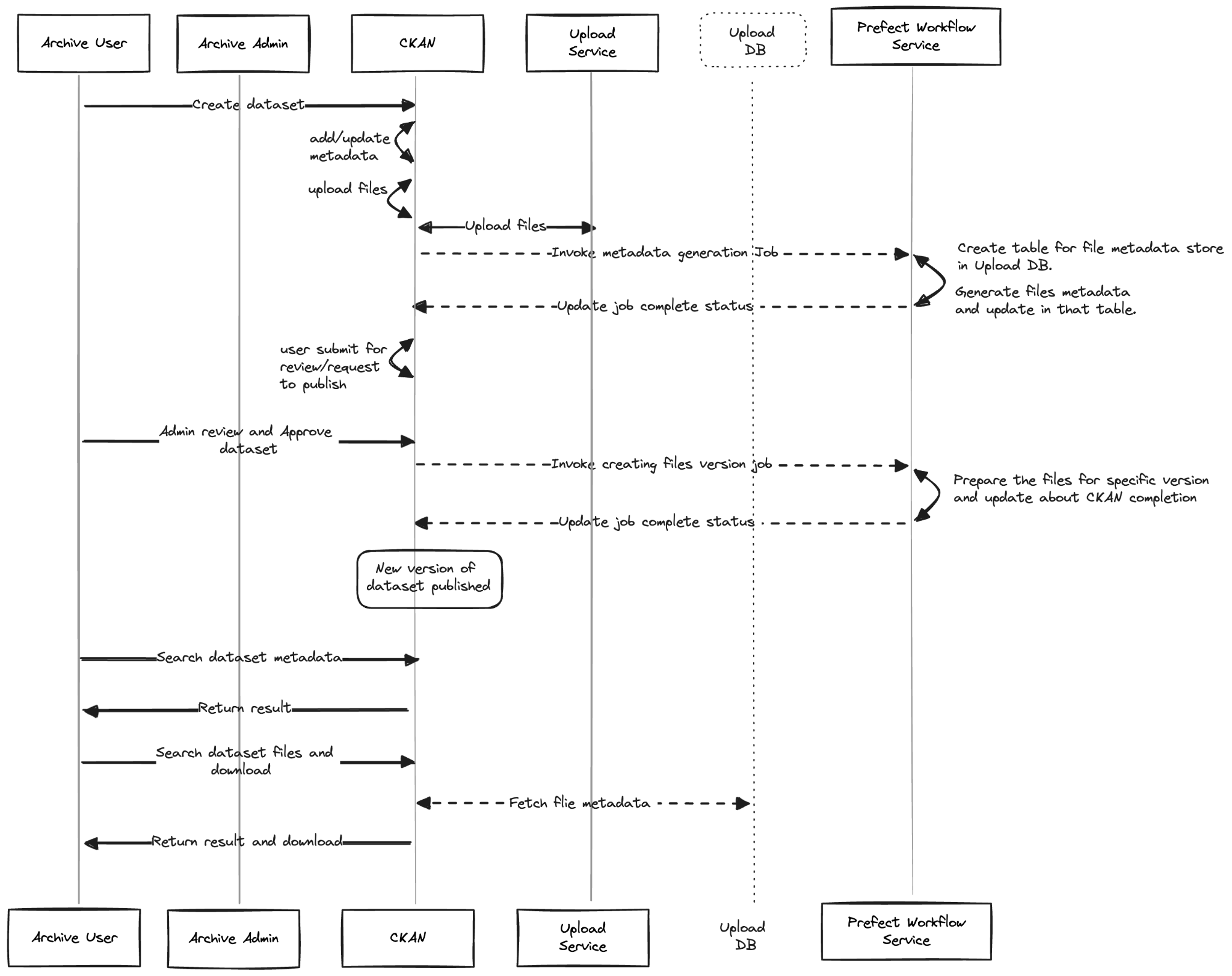
Versioning analysis Sagar https://hackmd.io/Z_swfitURlimERdVT5dg4w
27 Jun 2024
Sagar:
- Past:
- Deployed changes to the approval flow
- Reviewed Demenech's PR
- Had the technical discussion
- Next:
- Kick off on the versioning issue
Deme:
- Past
- Found a small bug related to the institutions being mapped to a dataset which he fixed (the PR that Sagar reviewed)
- Reviewed Ronaldo's PR
- Next
- Continue working on themes
Ronaldo:
- Past
- Created the footer
- Started working on the buttons I requested
- New
- Buttons
- After that, the organizations page on portaljs
Dragan:
- Past
- Almost finished themes-related backend work
- Next
- Help Joao if he needs help
- Create a snippet for rendering themes in dataset landing page
Parking lot
- Summary of technical discussion
- U5: Licenses access embargo
- One half is already solved: licenses is out-of-the-box in CKAN
- Access restriction or embargo:
- They have private and public areas in the storage. Restricted datasets are supposed to be in the private storage.
- Restricted datasets: metadata is public but data itself is not. User/creator should request access. Archive manager and sysadmin can see the restricted.
- They want to insert an embargo date. Archive manager to be notified once done so that. Metadata field.
- DANIELA to double check with Adil on what their understanding is. Metadata will be accessible but would the toc be accessible?
- U7: Versioning
- We clarifyied almost alll of the things. Asked almost every use case we could think of.
- Only one thing that Sagar is not 100% clear on: while adding and reviewing the file, they should be able to first review and then add. We will add one more step which is to download and edit the TOC.
- First step is removal. Then save. Then upload the changed TOC. Next step is adding new files.
- Next step is automatic. You upload files to temp storage. Cron job picks them and
- U5: Licenses access embargo
User should first delete the file from the TOC. and then upload. Why does it have to be in this order? User can add a new file and then remove the specific file from the TOC.
- First removing and saving the TOC.
- Replace the file with the same name. Deletion.
Situation
Currently, what we have is a Treemap and a FlatUITable visualizing this summary file: summary_52BC22E5-8380-4EAF-8855-5C312745550F.csv
It looks as follows:
Problem
With this size of file, it looks fine but we think that it will become problematic if we want to render it with a much bigger file eg. the TOC file Adil uploaded (143 MB) and that it won't be a scalable/viable solution. Both the table and the data visualization may be having weird or no output (or load super slowly and have bad performance) if we try loading the full TOC.
Solution
There are 3 options:
- Limit the number of rows we are displaying from the TOC file => useless according to Adil
- Display the TOC if less than X MB/rows and do not display it if bigger than that
- Do not display the TOC at all but just the summary information
resource file summary information will be along with the TOC in the resource file. Way to pick the beginning and the end of it so you can present a summary of it. It's great to display the summary information. Eg. just displaying only the first 5 lines of TOC is not very useful. It doesn't help anybody. The visualization is quite nice. Unless the table contains the summary information. I could use the path, append the s3 bit and download the entire directory. From this, I would be able to look at this and see how many files are there and how big the directory is
Anuar: Let's keep it simple. Let's do the visualization. We have the summary information and we need to visualize it.
Take the biggest summary file
15 May
In terms of next actions:
- What do we need from them? Setting up the s3 area. We need read and write access to staging (temporary storage) area.
- What are the next steps for our team?
- we need to test S3 storage first and then to think about next actions // provide estimates
When a user wants to upload data, we have 2 cases:
- if we have big datasets to upload, when a user comes to Upload a data page, will they be clicking on add resource/add file data, are they presented with some interface, or is an email sent? What's the process?
- CLI
- if we have less than 10 GB dataset
- we need to test the current implementation because we had some issues there. Uploading directly to the storage with the tus server via UI

April 16
- We have the requirements from the Sigma2 team in the form of Use cases and technical requirements.
- We have backlog refinement sessions every second week where we clarify the particular Use case we are planning on working on in the next 2 weeks. We clarify and get additional context and details around what is expected.
- We define the "Acceptance criteria" - when is the job going to be considered done
- We do technical analysis to plan out the solution (and how it fits within what we already built and what we are planning on building)
- We implement and deploy to the testing environment
- Internal review and testing: We have our integration tests where we test the functionality
- The client is testing and validating
- Once the client signs off, this is declared done and deployed to prod
The progress made and the current status can be seen by looking at our project board in Github. Happy to give access to whoever wants to have more visibility.
But also in the meetings. We are having the following regular sessions:
- Daily Standups (these are internal)
- Backlog refinement sessions (external)
- Sprint review and planning sessions (one internal and one external)
- Weekly syncs between me and Inger Lise
- Ad hoc meetings if we need to clarify or discuss a particular matter
In terms of tools, we love simplicity. Tools are not useful if not used right. we are using Github
Overview of what has been done so far Overview of what else is outstanding
- => What effort is involved behind
April 4
Sigma mockups:
- no description
- remove the collapse feature
- In a case of long list, difficult to display - add pagination
- Similar to r2 bucket or Google drive or Google Cloud storage
- Instead of folder name and 29 files, we need to have a path (breadcrumbs)
- When we enter subfolder, it should be in the path.
- No way to get back with this solution
ASK clients to test and validate from local storage. Third party seems to work. Test with real data. Why? We tested with 2 GB file already. Ask them to create 2 DBs for us
How much do we want to wait during the upload? Give us the limit because there is no technical limit. If the user wants to sit for 2 days and wait for the upload to happen. on the CLI, it will be similar. The user has to wait. the upload takes more than 2 hours,
Setting up the env locally https://hackmd.io/YhoBDyffToScc8S5xMLtyw
Inbox
**
-
Feedback on the old issue about logging. They should be tested.
-
Why Adil wants the changes
-
Ensure the team wants it
-
Find out the reasons or rationale behind it
-
No way to view the individual files uploaded to the resources
-
No way to delete the files individually, you have to delete the entire resource
**
26 Mar 2024
License Access rights Versioning - will be covered in use case 8
25 Mar 2024
Metadata schema
- There is a colon on the terms and conditions page. Can we remove it
- I didn't get because i dropped for bad internet connection. Did you say that some of the metadata fields are not implemented yet?
- Some spacing between the icon of the Upload and Link buttons on the Add data page
- Some spacing between the buttons below
BLOCKED Upload local storage:
- Set up Minio server on their infrastructure
- Test again
- Update the development stuff on the server
- Test the performance again
- If it works, we can consider the upload feature working incl. the metadata storage
BLOCKED Third-party storage upload:
- We need the subdomain from the client
- Point that domain in the server
- Test again if it works
Blockers update: @Sagar Ghimire @Dragan Avramovic see below the updates I just received from Sigma team:
-
Credentials to s3 bucket / storage – The credentials for S3 bucket is in place, and there has been some adjustment of ACL -SOLVED on Friday afternoon.
-
Gitlab access devs SOLVED – was solved today. They should have the same access as Shubham. Please let me know if it’s working.
-
Metadata schema - Need to go through comments from the meeting we had with the reference network today and tidy up. We will have this to you by Thursday.
-
What are all the current roles in Sigma2 system. Eg. in ckan, we have creator, maintainer, etc. in Sigma, we’re talking about depositor, author, etc. is there a way for us to get a list of these roles. We want to map them to our roles. The metadata schema will address these roles, but Adil will make a list and send to the project team today. Hopefully the project team will reply to this asap so we can have it to you by tomorrow.
User roles archive admin Q
@adilhasan I would like to clarify the Archive manager role with a few questions because I want to avoid a scenario where we add additional layers of roles within CKAN (user roles are hardcoded almost everywhere and if we can adopt the existing ones to serve that would be much better than making lots of changes to existing ones):
- How important is it that this person doesn't also have sysadmin rights? Think about whether you have already identified who would play this role within your organization and if so, if they could not have top-level access to both the archive service and to all archive datasets?
- Are you planning on utilizing the "Organizations" in CKAN? Because an archive admin sounds to me like the admin of all organizations which will give them i) access to all datasets, incl. private ones ii) permissions to edit all those if needed.
Metadata multiplicity
Password: wolf-pacing-mono-blanch
This is the dev site in progress: https://sigma2.prototyp.io/
http auth: sigma2 / sigma2023
Each file will be a resource A folder can be uploaded No checksum during upload and will be taken care on the server side
if we provide an API designed to change the metadata, would it be possible? Please check this. On the server side.
https://docs.pcloud.com/my_apps/ Please register the app and share the credentials with us
metadata schema and dynamic changes Use cases are interconnected and there are dependencies
- s3 credentials - we haven't received
Daniela TODOs
- Talk to Anuar re CKAN 3.0
- Request from Inger Lise that we change the plan we agreed at the beginning
12 Feb 2024
Current blockers
We need to test in their infra to understand how it works. Sagar asked Shubham to deploy but we need the following to be provided (blocked on 3 fronts):
- The container registry has not been provided (for the TOS upload deployment)
- Credentials to s3 bucket
- Gitlab access
If they unblock us today, we need to test tomorrow. And if it doesn't work well, we may not be able to demo on Wednesday.
Actions for us:
- Email to all that if they don't unblock us today, we won't be able to demo the upload functionality on Wednesday.
- **We need to ask Anuar and Shubham to give feedback on Sagar analysis doc ASAP https://hackmd.io/HGY8liWrRzWxshXStSTkiA
Actions for the devs:
- Dragan to drop his feedback on Sagar hackmd
- Sagar is currently exploring the CI upload / implementation ; we have UI and CI implementation;
- Sagar to create a separate subissue for this.
Stephen analysis https://hackmd.io/@steveoni/HJQVosrqT
Sagar analysis https://hackmd.io/HGY8liWrRzWxshXStSTkiA (expected inputs)
Tech stack for the project
Backend: We use CKAN in general as the data management service // we use this for the backend
- Solr engine
- Postgress (database)
- Repo for Project setup: https://github.com/datopian/dx-helm-sigma2
- docker-composer setup Frontend: We have decoupled frontend - PortalJS
CKAN has its own frontend and UI and we need to make changes in this UI mostly using JS for uploading files;
Questions for Sigma
- Are we going to display the number of private and embargo datasets in the hero section?
- Themes.
- Do you already know what topics/themes you will have and
- How many?
- Are you projecting that the number increases in time?
- Do you have associated images with these themes?
- Dataset metadata attributes on the search page:
- Currently, we have displayed the dataset AUTHOR on the mockup. This is the person who publishes the dataset in CKAN. I think you're calling this depositor. Can you please provide us with a list of the roles you have and what they mean (I image sth like a glossary)?
- Which role(s) would you want to have as metadata attributes on the search page?
- Filter facets: what filter facets do you require having? Eg. not sure that the timestamp one is even relevant, we took it from the prototype.
- On the prototype, per each dataset there is a field, a subfield and a domain. In ckan, we have topics and we can have hierarchy (subtopics). Can you give us the definitions of the field, subfield, and domain so that we know how to recreate this in CKAN?
- What is expected to display on the Citation tab on the dataset page? Will the user be able to perform any action there or is it just an informative list?
- Downloading a dataset. Can we just confirm that you mean being able to download all resources/files from the dataset and not the whole dataset in bulk?
- Tags. Design style. There was a comment from Franceska that the tags on the dataset page look like buttons. I would like to clarify something on the overall design style and guidelines.
- Monika tried to create a seamless experience between the mockups and the new design guidelines that were provided to us. However, the guidelines are unclear (maybe because they are in a shape of mockups). For example, there are 3 different ways of displaying buttons there, see screenshots

- Monika tried to create a seamless experience between the mockups and the new design guidelines that were provided to us. However, the guidelines are unclear (maybe because they are in a shape of mockups). For example, there are 3 different ways of displaying buttons there, see screenshots

 Which ones are we supposed to adapt and follow?
9. In the contact tab on the dataset page, which roles are to be displayed? Currently, we have Author (Creator) and Maintainer (Editor).
Which ones are we supposed to adapt and follow?
9. In the contact tab on the dataset page, which roles are to be displayed? Currently, we have Author (Creator) and Maintainer (Editor).
Actions for Monika
- Update the radio button in the filter facets to a checklist type.
- Remove the number of downloads from both the search and the dataset page